text_data=json.dumps({"message":"You are the Editor"})
)
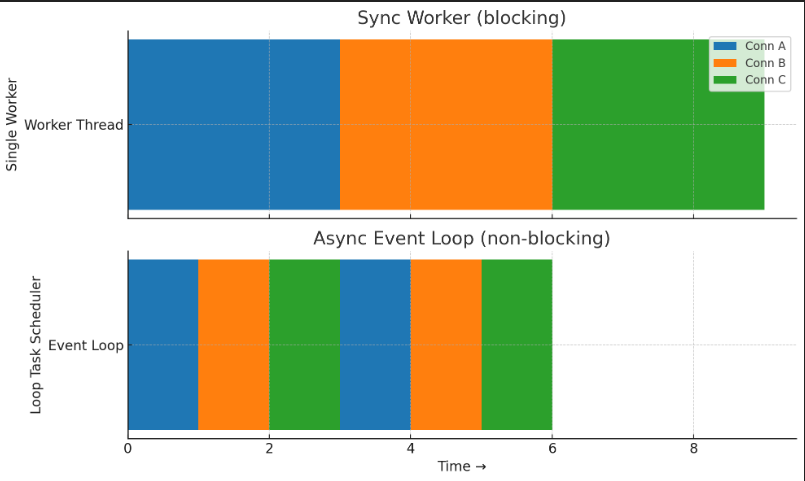
هر دو کد consumer هایی برای برقراری ارتباط websocket هستند. در اولی از ارتباط sync استفاده شده و در دومی از ارتباط async استفاده شده است.
در نتیجه:
در اولی:
اگر یک کانکشن برقرار شود، دیگر هیچ کانکشنی برقرار نمیشود تا کانکشن اولی بسته شود. چون کانکشن اول accept شده و هر کانکشن یک worker thread رو اشغال میکنه و تا زمانی که بسته نشه thread برای کانکشن بعدی باز نمیشه. این روش برای کارهای سریع مثل یه ارتباط با دیتابیس مناسب است اما برای یک ارتباط websocket که قرار است مدت زیادی باز بماند خوب نیست.
در دومی:
ارتباطات async است یعنی در واقع به آن گفته می شود که در قسمت await منتظر بمان تا I/O تکمیل شود اما در طول این انتظار ارتباطات دیگر می توانند برقرار شوند. در این حالت هر ارتباط به صورت یک task در event loop اجرا میشود. event loop ارتباطات دیگر را مدیریت میکند.
در واقع در حالت sync تسکها توسط worker ها انجام میشود و در حالت async تسک ها توسط event loop.
حالت sync مانند آشپزیست که هر قسمت غذا را کامل می پزد و بعد سراغ قسمت بعدی می رود اما حالت async چند ماهیتابه جلوی آشپز است که هر کدام را می چرخاند و سراغ بعدی می رود. این کار را event loop انجام می دهد که در پایتون در asyncio پیاده سازی شده است.
در دو consumer ای که نوشته شد هم داستان همین است. تا کانکشن اول بسته شود کانکشن بعدی باز نمی شود اما در حالت async این طور نیست و کانکشن اول در قسمت await وای میسه و event loop سراغ کانکشن های بعدی می رود.
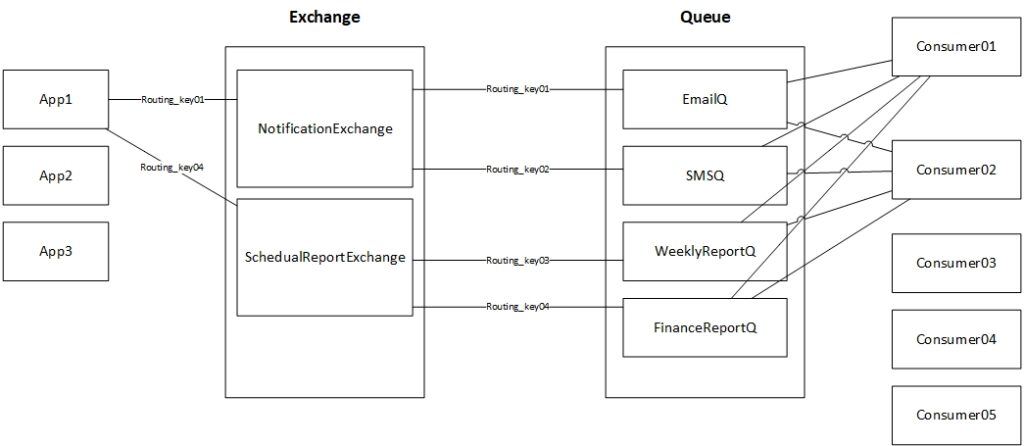
کی از Message Queue استفاده میکنیم؟ وقتی که قرار باشد پیامی بین process ها یا consumer ها جابجا شوند. در واقع هر وقت توی django channels از channel layer بخایم استفاده کنیم باید از message q استفاده کنیم. در واقع channel layer همان message queue است.
کلاسهای زیر را در نظر بگیرید. این مدل طراحی مشکلات زیادی به وجوده میاره. با آپدیت شدن کلاس اول مجبور هستیم کلاس دوم و سوم رو هم آپدیت کنیم که با فراموش این نکته توی قسمت های مختلف کد باگهای زیادی ایجاد میشه. و همین آپدیت های اضافی کدهای اضافی در نتیجه باگهای بیشتر و سرعت کمتر رو به ارمغان میاره
depenancy زیادی بین کلاسها میبینید. در صورت آپدیت یک Service باید دو کلاس دیگر هم آپدیت شود و این موضوعی نیست که اتوماتیک انجام شود و ایراداتی در نرم افزار ایجاد میکند:
Python
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
classService(models.Model,Template):
name=models.CharField(...)
name_fixed=models.CharField(...)
...
classLink(models.Model,Template):
provider=models.ForeignKey(
'Service'...)
provider_name=models.CharField(...)
consumer=models.ForeignKey(
'Service',...)
consumer_name=models.CharField(...)
.
.
.
classChain(models.Model):
pc=models.CharField(...)
provider_name=models.CharField(...)
consumer_name=models.CharField(...)
.
.
.
برای حل این موضوع باید کد را Normalize کنیم. یعنی تکرار به حداقل برسد و بجای تکرار اطلاعات موارد تکراری با کلید خارجی تبدیل شود:
Python
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
classService(models.Model,Template):
name=models.CharField(...)
name_fixed=models.CharField(...)
...
classLink(models.Model,Template):
provider=models.ForeignKey(
'Service'...)
consumer=models.ForeignKey(
'Service',...)
...
@property
defprovider_name(self):
returnself.provider.name
@property
defconsumer_name(self):
returnself.consumer.name
.
.
.
classChain(models.Model):
pc=models.CharField(...)
link=models.ForeignKey(Link,...)
...
@property
defprovider_name(self):
returnself.link.provider.name
@property
defconsumer_name(self):
returnself.link.consumer.name
حالا با آپدیت هر سرویس دو کلاس دیگر به صورت اتوماتیک آپدیت هستند.
گاهی Denormalization به درد میخورد. وقتی میخایم از یک جدول گزارشگیری داشته باشیم و نیاز به Join نباشد تکرار اطلاعات باعث افزایش بهره وری query می شود و …
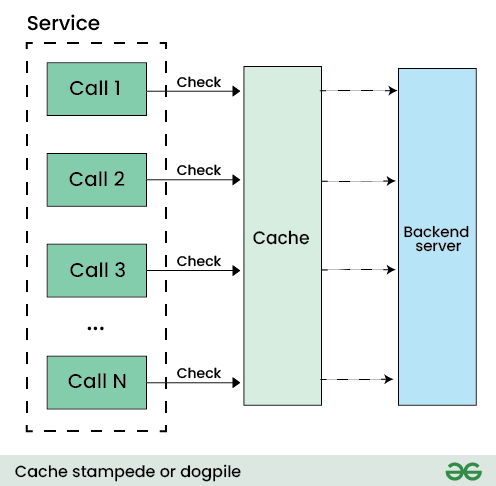
این مساله در علوم کامپیوتر به حالتی گفته میشود که یک cache که بسیار پراستفاده است منقضی میشود و همزمان تعداد بسیار زیادی از درخواست برای آن ارسال شده و در نتیجه چون منقضیست تمامی این درخواستها به دیتابیس ارسال میشود و موجب ازدحام دیتابیس میشود.
تنها در سیستمهایی این مشکل ایجاد میشود که سرویس مربوطه تنها با استفاده از cache دارای performance خوبی شده و قابل استفاده است و در این حالت دیگر سیستم قابل استفاده نخواهد بود.
در علوم کامپیوتر مساله ای مطرح است به نام “گله ی رعد آسا” یا Thundering Herd Problem.
وقتی که تعداد زیادی process منتظر یک رخداد یا event هستند، ولی وقتی که این event رخ داد تنها یکی از این process ها باید انجام گیرد. در این حالت بعد از رخداد یک process انجام میگردد و باقی آنها معطل میشوند و یا مکررا دوباره تلاش میکنند و در نتیجه سیستم هنگ میکند. این در حالیست که تنها یکی از آنها باید اجرا میشدند و باقی باید کنسل میشدند.
در UNIX این مشکل به این شکل حل شده است: همه پاسخها در یک file descriptor نوشته می شوند بنابراین پس از پاسخ تنها یکی از process ها یا thread ها اجرا میشوند (بجای اینکه همگی با هم اجرا و سیستم هنگ کند)
مثال دیگر:
فرض کنید یک API داریم و 500 پروسه این API را صدا میزنند. ولی این سرویس تنها میتواند 2 تای آنها را پاسخ دهد. و 488 مورد دیگر Fail می شوند. ولی دوباره تلاش میکنند و این بار این سرویس با 996 درخواست روبروست و مجددا تنها میتواند 2 تای آنها را پاسخ دهد و این سیکل تا زمانی ادامه پیدا میکند که سرویس مختل شود. این هم مثال دیگری از گله ی رعد آساست.
برای حل این مشکل راه حل این است که از فراخوانی اگر Fail شد پس از 2 به توان N ثانیه دوباره تلاش کند. بنابراین دفعه دوم بعد از 4 واحد زمانی سپس 8 ، 16 و… واحد زمانی دوباره تلاش میکند این فاصله زمانی که تابع نمایی exponential هست موجب می شود که سرویس فرصت بازسازی خود را داشته باشد. در ادامه این راه حل میتوان یک عدد تصادفی به عنوان jitter به این بازه زمانی اضافه کرد تا همه فراخوانی ها دوباره همزمان نشوند. یعنی فرمول فراخوانی مجدد میشود (T + 2**N + JITTER)
نیاز بود که توی یک جدول اگر توی سلول یکی از ستونها کلیک کردیم یک مودال باز بشود. اما باید اطلاعاتی مربوط به آن ردیف به مودال پاس بدیم. متوجه شدم که این اطلاعات مربوط به ردیف مذکور را میتوان به عنوان یک پایامتر به سلول مربوطه اضافه کرد مثل:
XHTML
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
<tbody>
{% for f in feedbacks %}
<tr>
<td
{%iff.active%}class="text-danger"{%endif%}
>
{% if f.active %} (فعال) {% endif %}v.{{f.feedback_version}}
الان توی اسکریپت زیر از هر ردیف سلول مربوطه رو بر اساس اسم کلاس میگیریم. بعد از اون سلول پارامترم مربوطه که دیتا بهش وصل شده رو بر میداریم بعد همون مقدارها رو به مودال میدیم:
با تبدیل اولی به دومی زمان این query از 450 میلی ثانیه به 45 میلی ثانیه کاهش پیدا کرد. چرا؟
دلیل این بود که فیلدهای این مدل همگی Index بودند اما این ایندکسها اعمال نمی شدند چونکه annotate باعث میشود که کل جدول اسکن شود و عملا ایندکسها بی فایده باشند بنابراین حداقل st=0 را به قبل از annotate انتقال دادیم و این باعث شد برای annotate که اتفاقا از WHERE استفاده میکند از ایندکس استفاده شود.
در کد اول اگر thumbnail توسط کاربر انتخاب نشود یک فایل از مسیر mag آپلود میشود. و هنگام پاک شدن آبجکت مربوطه، اگر این آبجکت دارای این فایل پیشفرض بود پاک نشود که البته در این کد مربوطه خود به خود پاک می شود. پس یک باگ وجود دارد. گذشته از این باگ اگر 1000 بار کاربر بدون thumbnail فایل آپلود کند 1000 فایل تکراری ذخیره میشود.
در ضمن اگر فایل بهر دلیلی پاک شود یا نام آن تغییر کند سیستم دچار مشکل میشود.
در کد دوم اما اگر کاربر فایلی انتخاب نکند هیچ فایل پیش فرضی آپلود نمیشود بنابراین فایل تکراری دیده نمی شود و فضا هدر نمی روند.
از طرفی یک فایل static پاک نشده و هرکجا یک سند thumbnail نداشته باشد با متد get_thumbnail_url این فایل نشان داده میشود و دیگر سیستم دچار باگهای ناخواسته نمی شود.