عکس زیر معماری و روند کار scrapy را نشان میدهد. روند کار خیلی جالبه
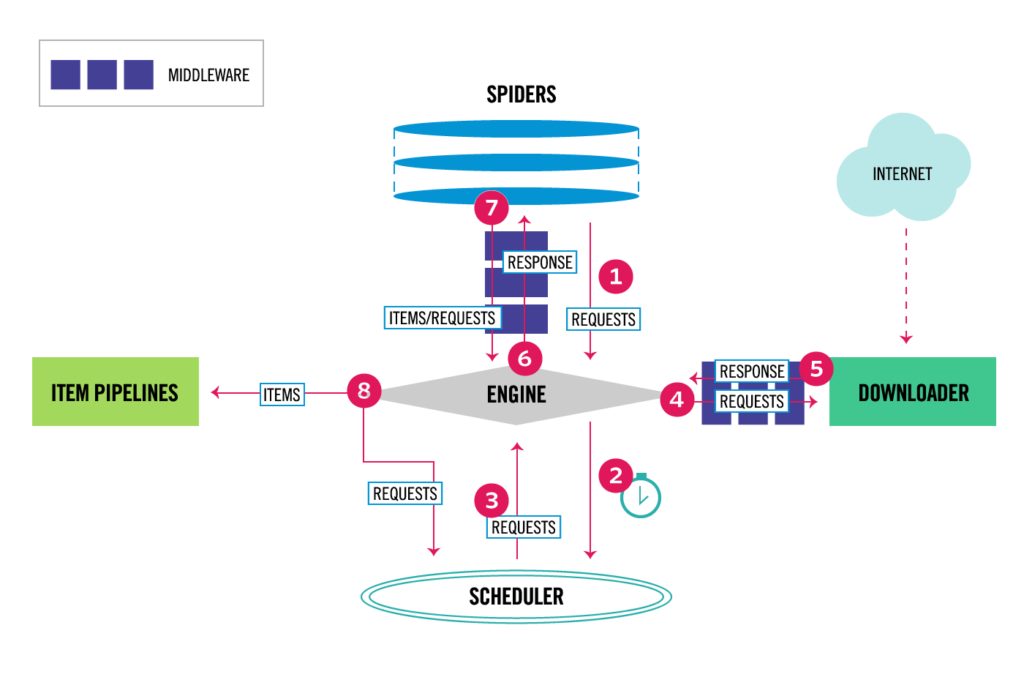
scrapy بخش های زیر رو داره
spiders: در واقع اون کدی هست که ما میزنیم و میخایم با روش خودمون از سایت های مختلف دیتا بگیریم و به روش خودمون ذخیره کنیم. در واقع اون کدی که ما میزنیم توی بخش spider قرار میگیره. مثلا میگیم از فلان سایت این قسمت های صفحه رو بگیر و ذخیره کن
Engine: موتور scrapy که در واقع مدیریت و ارتباطات بین اجزای مختلف رو داره
ITEM PIPELINES: توی این قسمت میگیم که دیتایی که گرفتیم چه بلایی سرش بیاد. مثلا بگیم توی دیتابیس یا فایل ذخیره بشه. تمیز کردن دیتا و صحت سنجیش هم همینجا انجام میشه.
Downloader: وظیفه گرفتن یک صفحه و دادنش به Engine رو داره
Scheduler: درخواست ها رو توی صف میزاره و سر وقتش به جریان میندازه
Downloader middleware: تمامی درخواست های بین Downloader و Engine از این واسط ها رد میشه. میتونه خیلی از درخواست ها رو بلاک کنه میتونه response ای که میگیره رو به Engine نده و با درخواست های بعد جمع کنه یه جا بده. درخواستهایی که جوابش رو داره دیگه نفرسته و هر چیزی رو کنترل کنه
Spider middleware: بین Engin و Spider میشینه درخواست ها رو به Engine میفرسته و جوابش رو به Spider میده از دوباره Item هایی که از Spider میاد رو بر میگردونه و این وسط تغییرات لازم رو انجام میده.
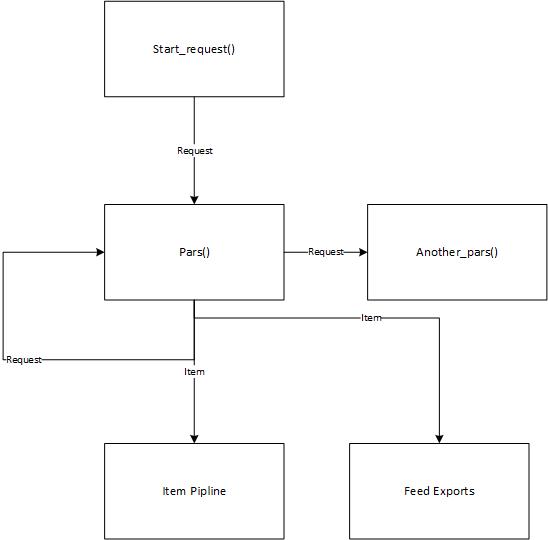
یه درخواست مسیرهای زیر رو میگذرونه توی Spider. عکس بالا یک Spider رو نشون میده.
اول متد start_request یک آبجکت Request رو به callback ای به اسم pars() میفرسته.
pars() اگه لازم باشه درخواست رو به یه callback دیگه میفرسته و درنهایت Response ای که از Downloader میگیره رو به Item تبدیل میکنه به Item pipline میفرسته که توی دیتابیس ذخیره بهشه یا به Feed Exports مفرسته که توی فایل ذخیره بشه