این مساله در علوم کامپیوتر به حالتی گفته میشود که یک cache که بسیار پراستفاده است منقضی میشود و همزمان تعداد بسیار زیادی از درخواست برای آن ارسال شده و در نتیجه چون منقضیست تمامی این درخواستها به دیتابیس ارسال میشود و موجب ازدحام دیتابیس میشود.
تنها در سیستمهایی این مشکل ایجاد میشود که سرویس مربوطه تنها با استفاده از cache دارای performance خوبی شده و قابل استفاده است و در این حالت دیگر سیستم قابل استفاده نخواهد بود.
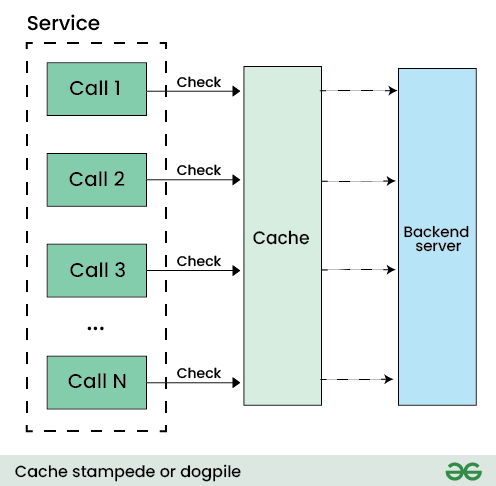
در علوم کامپیوتر مساله ای مطرح است به نام “گله ی رعد آسا” یا Thundering Herd Problem.
وقتی که تعداد زیادی process منتظر یک رخداد یا event هستند، ولی وقتی که این event رخ داد تنها یکی از این process ها باید انجام گیرد. در این حالت بعد از رخداد یک process انجام میگردد و باقی آنها معطل میشوند و یا مکررا دوباره تلاش میکنند و در نتیجه سیستم هنگ میکند. این در حالیست که تنها یکی از آنها باید اجرا میشدند و باقی باید کنسل میشدند.
در UNIX این مشکل به این شکل حل شده است: همه پاسخها در یک file descriptor نوشته می شوند بنابراین پس از پاسخ تنها یکی از process ها یا thread ها اجرا میشوند (بجای اینکه همگی با هم اجرا و سیستم هنگ کند)
مثال دیگر:
فرض کنید یک API داریم و 500 پروسه این API را صدا میزنند. ولی این سرویس تنها میتواند 2 تای آنها را پاسخ دهد. و 488 مورد دیگر Fail می شوند. ولی دوباره تلاش میکنند و این بار این سرویس با 996 درخواست روبروست و مجددا تنها میتواند 2 تای آنها را پاسخ دهد و این سیکل تا زمانی ادامه پیدا میکند که سرویس مختل شود. این هم مثال دیگری از گله ی رعد آساست.
برای حل این مشکل راه حل این است که از فراخوانی اگر Fail شد پس از 2 به توان N ثانیه دوباره تلاش کند. بنابراین دفعه دوم بعد از 4 واحد زمانی سپس 8 ، 16 و… واحد زمانی دوباره تلاش میکند این فاصله زمانی که تابع نمایی exponential هست موجب می شود که سرویس فرصت بازسازی خود را داشته باشد. در ادامه این راه حل میتوان یک عدد تصادفی به عنوان jitter به این بازه زمانی اضافه کرد تا همه فراخوانی ها دوباره همزمان نشوند. یعنی فرمول فراخوانی مجدد میشود (T + 2**N + JITTER)
از دیتابیس MySQL بک آپ گرفتیم به صورتی که این دیتابیس توی یک Docker Container بود که دیتای اون مپ شده به آدرس زیر. بنابراین با بک آپ از /var/lib/mysql تمامی دیتای این دیتابیس بک آپ گرفته میشه و میتونیم بعدا برداریم.
علاوه بر اون با استفاده از mysqldump هم از کل دیتابیس ها یک بک آپ توی فرمت sql گرفتم برای محکم کاری.
از طرفی این دیتا مربوط به یک وب اپلیکیشن هست که فایلهای آپلود شده و آواتارها و هر چیزی که آدرسش توی دیتابیس هست اما خود فایل توی /project/uploads ذخیره شده. بنابراین باید از این مسیر هم یک بک آپ بگیریم. نتیجه شد اسکریپت زیر:
در نرم افزاری طول URL از حدی که بیشتر میشد سرور ارور بر میگردوند. با بررسی لاگ Nginx و uWSIG متوجه شدم که سایز هدری که مرورگر میفرسته از حدی بیشتره و سرور قبول نمیکنه. از طرفی اون عملیات زمان بر هم بود و وقتی که سایز هدر را هم بیشتر کردم باز هم چون طول میکشید سرور کانکشن رو میبست. با تنظیمات Nginx زیر تونستم هم طول هدر رو بیشتر کنم هم مدت زمان کانکشن ها:
YAML
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
events{
worker_connections1024;
}
http{
include/etc/nginx/mime.types;
default_typeapplication/octet-stream;
sendfileon;
keepalive_timeout65;
client_header_timeout600s;
client_body_timeout600s;
send_timeout600s;
# limits the size of the client request body
client_max_body_size50M;
# These parameters control the buffer sizes used by NGINX when proxying responses from the upstream (uWSGI). Increasing buffer sizes allows NGINX to handle larger responses without having to offload data to disk
قبلا Nginx و uWSGI رو به صورت زیر اجرا کرده بودم که وقتی طول URL زیاد میشد ارور 502 میگرفتم. ارور رو بررسی که کردم دیدم uWSGI ارور میده. و ماکسیموم طول هدر برابر است با 4096 ولی طول این url بیشتره. Nginx رو به صورت زیر اجرا کرده بودم.
nginx.conf
Python
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
# nginx/nginx.conf
events{
worker_connections1024;
}
http{
include/etc/nginx/mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout65;
# Increase client body buffer and header buffer sizes
اما مشکل حل نشد. مشکل اینجا بود که Nginx به صورت پراکسی کل درخواست http رو به uWSGI میفرسته ولی بهتره که درخواست رو خودش پردازش کنه و بعد روی socket درخواست رو به uWSGI بده چون اون پروتکل wsgi رو بهتر و با پرفورمنس بهتر مدیریت میکنه.
قبلا uWSGI هم درخواست های http رو پردازش میکرد هم به عنوان یک application server درخواست های wsgi رو مدیریت میکرد یعنی Nginx یک reverse proxy معمولی بود ولی بهتره که http رو nginx مدیریت کنه و uWSGI به عنوان application server کار کنه که این از نظر پرفورمنس بهتره.
حالا که uWSGI رو روی socker کانفیگ کردیم باید Nginx هم درخواست ها رو روی socket بگیره و بده. بنابراین تنظیمات جدید به صورت زیر میشه:
Python
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
events{
worker_connections1024;
}
http{
include/etc/nginx/mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout65;
# Increase client body buffer and header buffer sizes
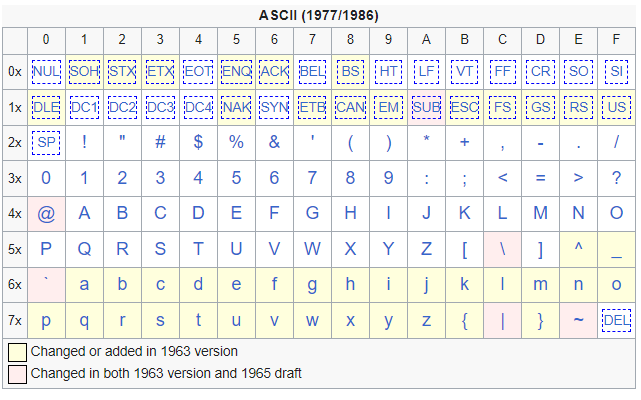
ASCII یک استاندارد کدگذاری داده هاست که توی ارتباطات کاربرد داره. این استانداره 128 کاراکتر داره که 95 عدد اون نوشتنی هستند. جدول زیر نشون دهنده کاراکترهای این استاندارد هستند.
بایناری که همان دودویی هست نقش مهمی توی کامپیوتر بازی میکنه خیلی از فایلها محتوای دودویی دارن مثل عکس ویدیو و pdf و هر فایل دیگه ای. علاوه بر همه اینها ممکنه توی یک برنامه یک آبجکت یا داده ساختار هم باشه که طبیعتا این هم دودویی هست. شامل 0 و 1
نکته مهم اینه که خیلی از پروتکل های ارتباطی قابلیت ارسال محتوای دودویی رو ندارن مثل HTTP یا SMTP یعنی اگر یک ایمیل داشته باشید نمیتونید باهاش فایل بایناری بفرستید. ولی ما همه تست کردیم و شده چراکه اون اپلیکیشن ایمیل اول اون فایل دودویی رو به یک استاندارد دیگه تبدیل میکنه و میفرسته و در مقصد هم اون رو دوباره به دودویی تبدیل میکنه و تحویل گیرنده میده. چراکه پروتکل های گفته شده بر اساس تکست کار میکنن محتوایی که قابل پرینت شدن باشن نه دودویی. بنابراین اگر از طریق این پروتکل ها یا توی JSON بخوایم یک محتوای دودویی بفرستیم اول باید به تکست encode بشه بعد توی مقسد از تکست به بایناری decode بشه.
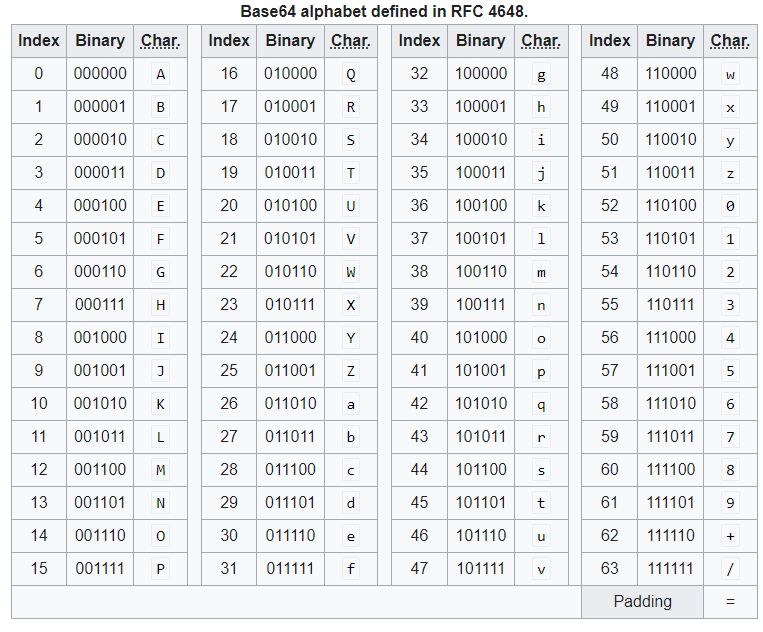
استانداردی که برای این کار استفاده میشه Base64 هست. Base64 مخصوص تبدیل کردن محتوای دودویی به ASCII های قابل چاپ هست. کاراکترهای موجود در Base64 شامل A تا Z به اضافه a تا z به اضافه 0 تا 9 به اضافه + / = هستند. یعنی از 000000 تا 111111 رو شامل میشه بنابراین هر بایت به یک کاراکتر تبدیل میشه و میتونیم روی وب یا پروتکل های دیگه که بر اساس تکست کار میکنن بفرستیم.
آیا فرستادن فایل های بایناری روی وب و تبدیل به Base64 کار خوبیه؟ کاربردهایش چیه؟
1.اتچ کردن فایل بایناری توی ایمیل
2.ارسال فایل بایناری روی HTTP یا SMTP با JSON یا XML
3.ذخیره کردن آبجکتهای کوچیک بایناری توی فایل متنی
4.امبد کردن فایل های بایناری مثل عکس توی HTMLیا CSS
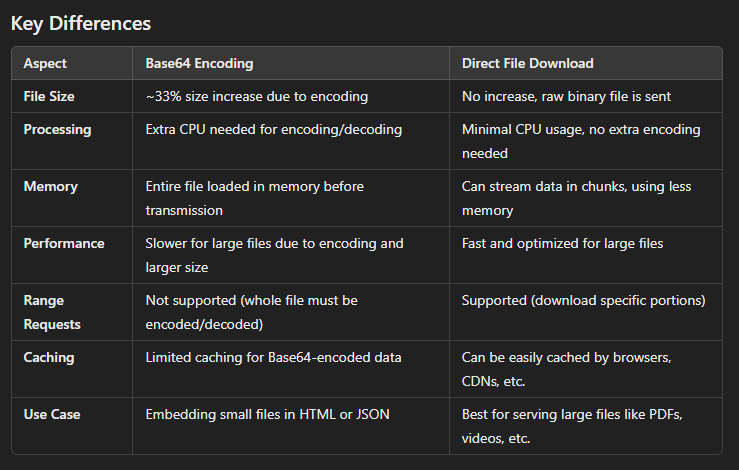
استفاده از Base64 حدود 33 درصد افزایش حجم خواهد داشت بنابراین استفاده از این برای فایل بزرگ توصیه نمیشه. برای فایلهای حجیم باید فایل مستقیم بدون encodeشدن از سرور دانلود شه چرا که تبدیل حجم زیاد خودش از هر نظر هزینه بر هست و فایل حجیم هم نیازی نیست که توی HTML بخوایم امبد کنیم و بهتره لینک دانلود بدیم یا استریم کنیم.
حالا ما میخوایم یک فایل pdf توی بروزر نشون بدیم یک راه حل اینه که فایل رو مستقیم لینک بدیم توی فرانت اند از pdf viewer خود بروزر استفاده کنیم یا iframe چون این دوتا میتونن فایل pdf که بایناری هست رو نشون بدن.
به دلایلی من تصمیم گرفتم که pdf رو هر صفحه شو به یک عکس تبدیل کنم و توی فرانت نشون بدم آیا میتونم این کار رو بکنم. HTTP میتونه فایل بایناری بفرسته ولی توی HTML نمیتونم فایل بایناری امبد کنم اصلا base64 برای همین اختراع شده که تبدیلش کنم به base64 که توی html قرار بگیره.
حالا میتونم توی بک اند تبدلیش کنم به base64 و بفرستم سمت فرانت و فرانت مستقیم بزاره توی html یا میتونم pdf رو به صورت بایناری بفرستم فرانت و اونجا base64 اش کنم و توی فرانت بزارم توی html. ترجیه میدم توی بک اند این کار رو بکنم.
توی کد بالا یک صفحه از pdf رو میگیره و از بایناری تبدیلش میکنه به Base64 که برای امبد شدن توی HTML خوبه و میفرسته و ابته قبل از فرستادن تبدیل میکنه به utf-8 و این دیگه چیه؟
مساله اینجاست که تابع bs64encode فایل بایناری رو به کاراکترهای Base64 تبدیل میکنه ولی هنوز هم تایپش بایناریه یعنی مقدارش کاراکتر base64 ولی وقتی میزنیم print(type(… میبینیم که بایناری هست نوعش مثل b’VGhpcyBpcyBhIGJhc2U2NCBlbmNvZGVkIHN0cmluZw==’
خوب این مشکلش چیه توی پایتون مشکلی پیش نمیاد چون ظاهرا پایتون میخات بفرسته تبدلیش میکنه به str ولی برای اینکه explicit باشیم باید به utf-8 اونو دیکد کنیم که دیگه تایپش هم str بشه. در ضمن بروزر های مدرن هم این تبدیل رو خودشون ظاهرا هوشمندانه انجام میدن.
ببینید ما اول بایناری رو تبدیل کردیم به base64 و همینطور که توی جدول ها معلومه base64 خودش زیرمجموعه ASCII هست و از طرفی خود ASCII زیرمتجموعه UTF-8 هست بنابراین توی این کیس مشکل خاصی هم پیش نمیاد. ولی اگر تبدیل برعکس باشه ممکنه مشکل ایجاد بشه.
حالا که همه چی اوکی هست چرا نهایتا باید تبدیل کنیم به utf-8 وقتی که خود بروزر و پایتون می فهمند که string هستن.
1.باید Explicit باشیم. شاید در آینده مشکلی پیش بیاد بهتره مستقیم خودمون تبدیل کنیم به utf-8 که تبدیل به string بشه
2.رشته string و utf-8 استاندارد وب هست. وقتی با وب کار میکنیم همیشه تبدیل کنیم به utf-8
3.شاید یک اپلیکیشن یا بروزر صراحتا به string بودن داده گیر بده پس استاندارد وب رو رعایت کنیم
پینوشت خود utf-8 چیه؟
utf-8 استاندارد کد کردن محتوا و بیشترین انطباق رو با unicode داره یعنی خیالمون راحته که اکثر زبانها و کاراکتر های چاپی و غیرچاپی رو شامل میشه. توسط بیشتر از 95 درصد مرورگرها پشتیبانی میشه و Unix هم کاملا باهاش کار میکنه. پس از این به بعد خواستیم داده ای انتقال بدیم بهتره تبدیل کنیم به utf-8.
اگر بایناری بود اول تبدیل کنیم به base64 که از بایناری به محتوای متنی تبدیل بشه بعد تبدیلش کنیم به utf-8 که توی بهترین استاندارد و در type یک رشته string باهاش کار کنیم.
بعد از نصب داکر فایلهای مورد استفاده خود داکر از قبلی image هایی که load میکنید توی مسیر /var/lib/docker ذخیره میشه که میتونه بعد از مدتی پر شه یا اصلا شاید بخاید جای دیگه ای ذخیره بشه. من خودم چون پارتیشن دیگه ای با حجم بیشتر دارم خواستم یه دایرکتوری دیگه رو map کنم به این دایرکتوری. البته روش های مختلفی وجود داره برای تغییر مسیر اما بهترین روش با کمترین impact این روشه: